

AI and Machine Learning seem to grab all the limelight in the tech world lately. I wanted to foray into it for a long time and as soon as I got the chance, I started playing around with Tensorflow, Keras and dived deep into it with neural networks and deep learning and let me tell you, it was one of the most amazing experiences!
I played around with fundamental problems initially, reading around basic concepts, went through GitHub repositories of people who have been doing exciting things in the field of ML, read hundreds of blog posts which built up my excitement even more.
One day, while texting around with a couple of my friends, the automatic emoji suggestions coming on the top of my keyboard as I was typing, caught my attention. I was interested in knowing how the contexts are being picked up and the related emoji was being suggested for the same. For example, something like,
“Congratulations on the promotion! ” would bring up a thumb up ?
or
“Let’s meet for a coffee” would suggest a ☕
or
“Love you!” would give me a ❤
I thought of building a similar ML model which would bring up emoji suggestions by understanding the context of the conversation. Read along to find out how it was done.
Preparation
I built an “Emoji Neural Network” using Tensorflow.
Firstly, I trained the model with the dataset (X, Y) where:
- X contained 20000 sentences
- Y contained an integer label between 0 and 4 corresponding to an emoji for each sentence, like so.
label emoji code
0 ❤ Heart
1 ⚾ Baseball
2 ? Smile
3 ? Disappointed
4 ☕ Coffee
The sample training set looked something like this:
X (input-sentence) Y (label)
1. work is horrible 3
2. valentine day is near 0
3. Let us go play baseball 1
Model
Now, let’s go deeper into the intricacies of the neural network I used to solve the problem.
Neural Network diagram (Source: tw.saowen.com)
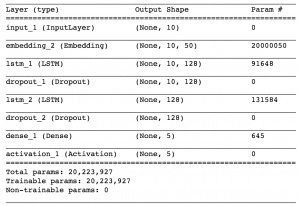
Layers used in Emojify:
- Embedding layer ( GloVe.6B.50d )
- Two LSTM layer (Long Term Short Memory)
- Two Dropout layer
- Finally, a Dense layer with Softmax activation to get back 5-dimensional vectors.
It’s an LSTM model that takes input as word sequences and is able to take word order into account. It uses pre-trained word embeddings to represent words, feed them into an LSTM network, whose job it is to predict the most appropriate emoji.
The Embedding layer
In Keras, the embedding matrix is treated as “layer”. It maps positive integers i.e. indices corresponding to words into vectors of fixed size. It can be initialized with a pre-trained embedding. Read more about Embedding layer in Keras, here.
In my case, I initialized the embedding layer with the GloVe-6B 50-dimensional vectors. Because the training set is quite small, I did not update the word embeddings but instead left their values fixed. Keras allows you to either train or fix the values for this layer.
The embedding layer takes an integer matrix of size as input and corresponds to sentences converted into lists of indices/integers.
The first step is to convert all your training sentences into lists of indices, and then zero-pad all these lists so that their length is the length of the longest sentence.
At this point, we have a meaningful numerical representation of sentences which we can feed into the LSTM layer.
Why have I chosen LSTM RNNs neural network:
Basically, the idea behind RNNs is to make use of sequential information. In a typical neural network, we go with an assumption that all inputs (and outputs) are independent of each other. But for many other problems, it may not work. Another good thing about RNNs is that they have a “memory” which captures information about what has been calculated so far. In practice, RNNs are limited to make use of information in arbitrarily long sequences, but in practice, they are limited to looking back only a few steps. So I have chosen the LSTM which is an extension of RNNs.
LSTM networks do not have much of a fundamental difference in architecture from RNNs. They make use of a different function to compute the hidden state using the memory in LSTMs (also known as cells) and It’s a black box that takes an input of the previous state h(t-1) and current input x(t). Internally these cells decide what to keep in and delete from memory and combine the previous state, the current memory, and the input. These types of units capture long-term dependencies very efficiently.
Softmax Layer:
Softmax calculates a probability for every possible class. In our case, it returns a 5-dimensional vector representing the probability of each emoji.
Tensorflow Model summary:

Conclusion
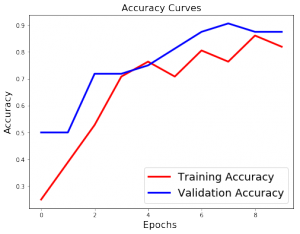
The model achieved the accuracy of 86% which is quite phenomenal. I enjoyed doing this side project a lot and would love to hear out your advice or pointers. Feel free to comment below about this it or of your own experiences while implementing any LSTM model.


